Les commits et les branches
Dans cette série consacrée à l’apprentissage pratique de Git à travers des exemples, après avoir vu ce qu’est un commit, nous étudierons comment s’organisent les commits et comment passer de l’un à l’autre.
Objectif
Comme nous l’avons vu à la partie 2 et à la partie 3, Git enregistre les modifications qui surviennent au code dans le dépôt sous forme de commits.
Au fil des commits, nous construisons donc un historique des nos modifications. Git nous permet de naviguer entre ces modifications et donc de retrouver les états antérieurs des sources dans notre dépôt. Nous allons aujourd’hui détailler les possibilités offertes par cette organisation des commits.
État initial du dépôt
Nous nous positionnons dans un dépôt Git contenant actuellement deux fichiers.
$ cd historique-commit
$ ls
file1 file2Le dépôt Git a connu 4 commits, comme nous l’indique la commande git log.
$ git log
commit ab63aad1cfa5dd4f33eae1b9f6baf472ec19f2ee (HEAD -> master)
Author: Carl Chenet <chaica@ohmytux.com>
Date: Tue May 28 20:46:53 2019 +0200
adding a line into file 2
commit 7b6882a5148bb6a2cd240dac4d339f45c1c51738
Author: Carl Chenet <chaica@ohmytux.com>
Date: Tue May 28 20:46:14 2019 +0200
add a second file
commit ce9804dee8a2eac55490f3aee189a3c67865481c
Author: Carl Chenet <chaica@ohmytux.com>
Date: Tue May 28 20:45:21 2019 +0200
adding a line in file 1
commit 667b2590fedd4673cfa4e219823c51768eeaf47b
Author: Carl Chenet <chaica@ohmytux.com>
Date: Tue May 28 20:44:30 2019 +0200
first commitLa commande git status nous précise quant à elle qu’aucun travail n’est en cours.
$ git status
On branch master
nothing to commit, working tree cleanAffichons le dernier fichier modifié pour la suite de l’article.
$ cat file2
this is the number 2 file
adding a line into file 2Retrouver un état antérieur
Nous allons maintenant tenter de retrouver un état antérieur de notre dépôt, à savoir l’état de notre dépôt au précédent commit.
La commande git checkout va nous permettre de revenir à l’état de notre dépôt à un certain commit. Nous pouvons utiliser pour ça un nombre de commits antérieurs, par exemple juste 1 commit avant :
$ git checkout HEAD~1Nous pouvons également utiliser l’identifiant du commit.
$ git checkout 7b6882a5148bb6a2cd240dac4d339f45c1c51738
Note: checking out '7b6882a5148bb6a2cd240dac4d339f45c1c51738'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -b with the checkout command again. Example:
git checkout -b <new-branch-name>
HEAD is now at 7b6882a add a second fileLa sortie de Git est un peu difficile à comprendre tout de suite, mais le fait est que nous sommes revenus à l’état du dépôt à l’avant-dernier commit.
Affichons le dernier fichier que nous avons modifié.
$ cat file2
this is the number 2 fileSon contenu a bien changé, nous sommes donc bien revenus en arrière dans l’histoire des modifications de notre dépôt.
Le pointeur HEAD
Un composant important de la commande git précédente reste assez obscure : que signifie HEAD ? Et pourquoi ~1 ?
Il s’agit tout simplement d’un pointeur de position parmi les commits de notre dépôt. Un pointeur est ici un repère logique, un petit drapeau au sein de Git, qui indique un commit et que l’on peut déplacer pour indiquer un autre commit.
Un schéma va nous aider à comprendre. Nous identifions les commits par les 4 derniers caractères de leurs identifiants.
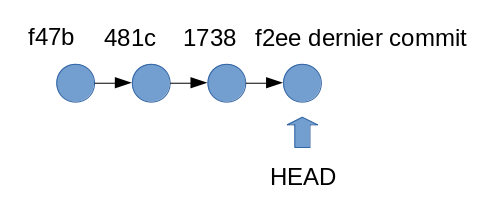
Avant notre checkout, HEAD pointait sur le dernier commit réalisé. Après le git checkout HEAD~1, nous avons positionné HEAD sur l’avant-dernier commit.
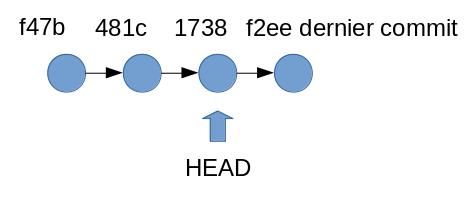
Nous entrons dans un mode spécial de Git (detached head ou tête détachée), qui nous permet de retrouver les données du dépôt telles qu’elles étaient au moment de ce commit. À partir de cet état du dépôt, nous pourrons évoluer vers un autre état sans modifier les commits déjà existants.
Différences entre deux commits
Nous allons maintenant observer les différences entre le commit sur lequel nous sommes positionnés et le commit le plus avancé que nous avons écrit, à l’aide de la commande git diff.
$ git diff HEAD master
diff --git a/file2 b/file2
index a21d8c9..040c455 100644
--- a/file2
+++ b/file2
@@ -1 +1,3 @@
this is the number 2 file
+
+adding a line into file 2Nous voyons bien la ligne ajoutée au fichier file2 lors du dernier commit.
Remarquons que nous avons utilisé dans notre commande master, avec HEAD. Ici HEAD point sur l’avant-dernier commit de notre liste. Nous voyons les différences entre l’avant-dernier et le dernier commit. Or le dernier argument de notre ligne de commande était master. Il s’agit donc aussi, comme HEAD, d’un pointeur, mais sur le dernier commit réalisé. Nous y reviendrons.
Cette commande git diff marche bien sûr avec n’importe quel identifiant de commit, par exemple voici la différence entre le premier et le second commit, en utilisant ici leur identifiant unique.
$ git diff 667b2590fedd4673cfa4e219823c51768eeaf47b ce9804dee8a2eac55490f3aee189a3c67865481c
diff --git a/file1 b/file1
index 9dd524a..2788b18 100644
--- a/file1
+++ b/file1
@@ -1 +1,3 @@
this is the number 1 file
+
+adding a line in file 1Les différences entre le premier et le second commit apparaissent bien.
Écrire une suite différente : une nouvelle branche
Nous sommes donc positionnés sur l’avant-dernier commit. Nous nous apercevons que nous aimerions continuer avec un contenu différent que celui enregistré dans le dernier commit, sans toutefois effacer ce dernier commit. Pour résumer nous voulons créer un embranchement dans l’histoire de nos commits pour créer une suite différente. Nous allons donc créer notre première branche.
Pour cela il suffit de relire le dernier message affichée lors de notre commande git checkout HEAD~1 :
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -b with the checkout command again. Example:
git checkout -b <new-branch-name>Nous allons donc passer la commande suivante afin de créer une nouvelle branche dans laquelle nous écrirons la nouvelle suite des modifications que nous souhaitons.
$ git checkout -b new-file
$ git status
On branch new-file
nothing to commit, working tree cleanRemarquons la première ligne On branch new-file alors que jusqu’ici nous avions On branch master. Nous avons donc bien créé une nouvelle branche nommée new-file.
Nous créons maintenant un nouveau commit contenant un nouveau fichier et l’ajoutons au dépôt.
$ echo "An unexpected new file" > file3
$ git add file3
$ git commit file3 -m "create an unexpected file"
[new-file a2e05c3] create an unexpected file
1 file changed, 1 insertion(+)
create mode 100644 file3Où en sommes-nous ? Un schéma vaut mieux qu’un long discours.
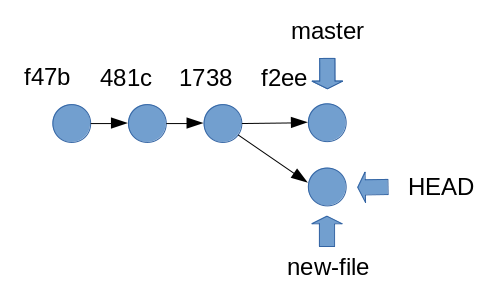
Ce schéma nous apprend beaucoup de choses :
-
notre première série de commits finit par un commit
f2eesur lequel un pointeur nommémasterest positionné. Il s’agit de la branchemaster -
De la même façon, la branche
new-filepointe sur notre dernier commit. -
Le pointeur
HEADindique l’état du dépôt sur lequel on travaille.
Une branche est donc définie par une série de commits et un pointeur du nom de cette branche sur le dernier commit de cette branche.
Conclusion
Arrêtons-nous là pour l’instant. Nous avons vu une notion fondamentale, à savoir ce qu’est rééllement une branche Git et les principes sous-jacents à une branche, le lien entre les commits et les pointeurs. Il était malheureusement difficile de parler des branches précisément (ce que nous avions fait dans notre première partie) sans toutes ces notions.
Dans un dépôt Git, l’unité est le commit, qui est un ensemble de modifications survenus sur le code dans ce dépôt. Un commit et ses prédecesseurs représentent une branche. On positionne sur certains commits des pointeurs, ayant chacun un rôle distinct :
-
Le pointeur nommé
masterpointe sur le dernier commit de la branchemaster. -
Le pointeur
new-filepointe sur le dernier commit de la branche éponyme. -
Un pointeur spécial nommé
HEADindique en permanence l’état du dépôt au dernier commit pointé par le pointeurHEAD.
Nous verrons dans une prochaine partie comment les branches interagissent entre elles et comment les utiliser pour multiplier les différentes versions d’un travail en cours.